
The CLEAR Benchmark:
Continual LEArning on Real-World Imagery
(New!) Wikipedia page for comprehensive documentation of CLEAR-10/CLEAR-100

Please check out our new wikipedia page for full documentation on CLEAR-10 and CLEAR-100 (released in July 2022). It comes with download links to the train set and (newly released) test set of CLEAR-10 and CLEAR-100, as well as summary of the 1st CLEAR challenge hosted on CVPR'22 Open World Vision Workshop and AICrowd. This site is preserved as a presentation of our NeurIPS'21 paper on The CLEAR Benchmark: Continual LEArning on Real-World Imagery.
Overview of CLEAR Benchmark

Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today’s testset can be repurposed for tomorrow’s trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).
Useful Links
- Arxiv paper (NeurIPS 2021 Datasets and Benchmarks Track)
- CLEAR-10 links:
- CLEAR-100 links:
- AICrowd platform for 1st CLEAR Challenge hosted on CVPR 2022
- Avalanche integration for CLEAR-10/CLEAR-100 (sample training script)
- Github repository for dataset curation (YFCC100M download & CLIP-based retreival & MoCo pre-training)
- Github repository for training and evaluation code in NeurIPS'21 paper
- CLEAR-10 (old google drive link) | Zipped version | Folder structure explained
CLEAR Collection Pipeline
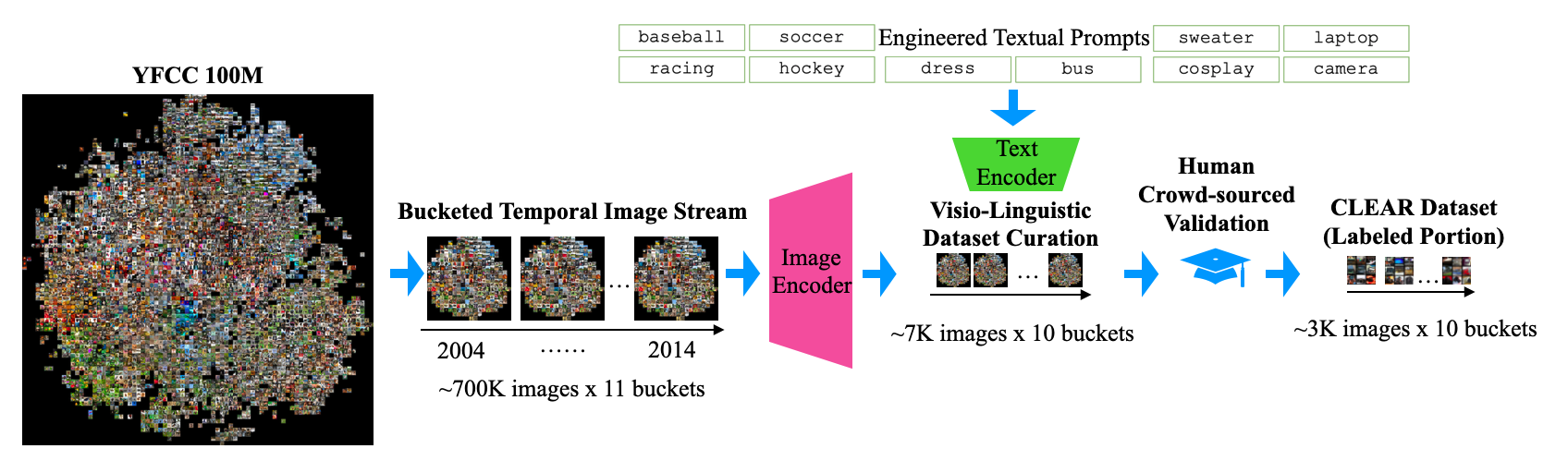
Since it is non-trivial to download the entire YFCC100M dataset (over 10TB), we first download the metadata files (50GB) and download a random subset of 7.8M images from it. Then we use the upload time to recreate the temporal stream and split them into 11 segments of 0.7M images. Given a temporal segment of images and a list of queries (found by text-prompt engineering in order to effectively retrieve the visual concepts of interest), we use a pre-trained vision-language model CLIP to extract their respective L2-normalized image and query features. We can measure how much an image is aligned to a particular query by computing the cosine similiarity score (e.g., dot product) between the two features. For each query, we can rank all the images and only retrieve the ones with highest scores. Finally, we hire MTurk workers to verify the retrieved images for each class and remove sensitive images hidden in original YFCC100M collection.
IID vs Streaming Protocols for CL
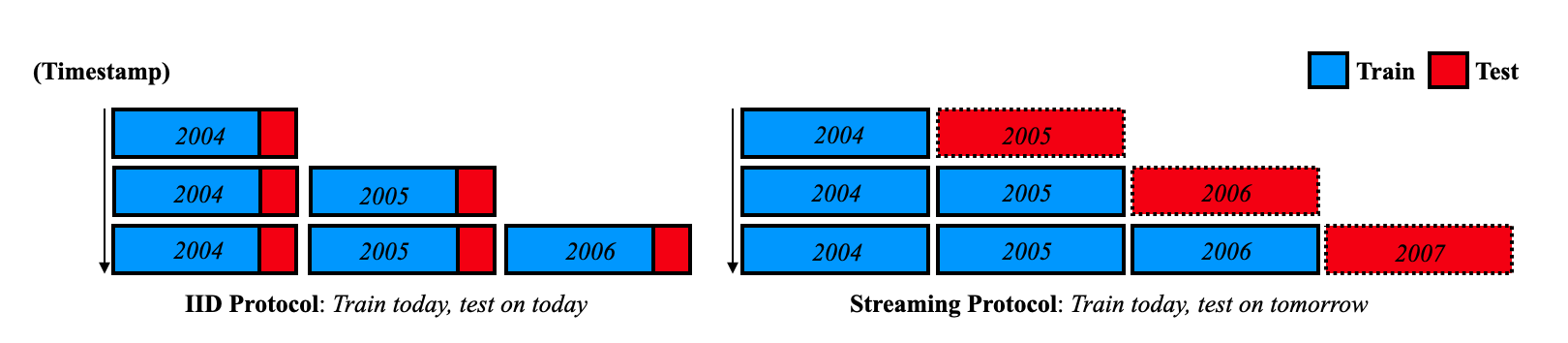
Traditional CL protocols (left) split incoming data buckets into a train/test split, typically 70/30%. However, this may overestimate performance since the train and test data are drawn from the same iid distribution, ignoring the train-test domain gap. We advocate a streaming protocol (right) where one must always evaluate on near-future data. This allows us to repurpose today’s testset as tomorrow’s trainset, increasing the total amount of recent data available for both training and testing. Note that the streaming protocol naturally allows for asynchronous training and testing; by the end of year 2006, one can train a model on data up to 2006, but needs additional data from 2007 to test it.
Streaming Protocols for Continual Supervised vs. Un-/Semi-supervised Learning

We compare streaming protocols for continual supervised (left) and un-/semi-supervised learning (right). In real world, most incoming data will not be labeled due to the annotation cost; it is more natural to assume a small labeled subset along with large-scale unlabeled samples per time period. In this work, we achieve great performance boosts by only utilizing unlabeled samples in the first time period (bucket 0 th) for a self-supervised pre-training step. Therefore, we encourage future works to embrace unlabeled samples in later buckets for continual semi-supervised learning.
Workshop and Competition Information
We hosted a CLEAR-10/CLEAR-100 challenge on 2nd Open World Vision workshop (CVPR2022). A summary of the challenge in our slidesdeck!
Citing this work
If you find this work useful in your research, please consider citing:
@inproceedings{lin2021clear,
title={The CLEAR Benchmark: Continual LEArning on Real-World Imagery},
author={Lin, Zhiqiu and Shi, Jia and Pathak, Deepak and Ramanan, Deva},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2021}}
License
This project is under CC BY licenseAcknowledgements
This research was supported by CMU Argo AI Center for Autonomous Vehicle Research.